통계를 처음 공부할 때, 마주하는 아주 중요한 개념들이 있다.
특히 통계적인 검정을 하고자 할 때, 기초적 검정이든 고급 검정이든 이번에 정리하고자 하는 개념들은 항상 사용되기 때문에 확실하게 알고 가는 것이 좋다. (항상 헷갈림)
📙 1. 통계학개론과 같은 교재에서 '검정(hypothesis test)' 파트에 도달하면 가장 먼저 나오는 단어(?) 중에 하나가 '알파α'이다.
통계에서 알파α는 유의 수준(significance level)이라는 개념을 갖고 있다.
유의 수준은 제 1종의 오류(=귀무가설이 사실인데 기각하는 오류)를 허용할 확률이다. 유의 수준으로는 5%가 많이 사용되는데, 이는 제 1종의 오류를 허용할 확률이 5%라는 의미이다. 따라서 통계 검정시 유의 확률(p-value)이 유의 수준(significance level)인 5%보다 작으면 귀무가설을 기각하게 되는 것이다.
알파를 간단하게 정리하면 다음과 같이 나타낼 수 있다.
📌 알파 = 유의 수준 = 제 1종의 오류 = 위양성
α (alpha) = significance level = type 1 error = false positive
📘 2. 검정(hypothesis test) 파트에서 알파 다음으로 나오는 개념이 '베타β'이다.
알파α가 제 1종의 오류를 나타냈다면, 베타β는 제 2종의 오류(=귀무가설이 거짓인데도 기각하지 않는 오류)를 나타낸다. 제 2종의 오류는 제 1종의 오류보다는 상대적으로 덜 치명적이긴 하지만, 여전히 오류라는 사실을 벗어날 수 없다.
베타를 간단하게 정리하면 다음과 같이 나타낼 수 있다.
📌 베타 = 제 2종의 오류 = 위음성
β (beta) = type 2 error = false negative
이를 그림으로 나타나면 다음과 같다. (출처는 scribbr)
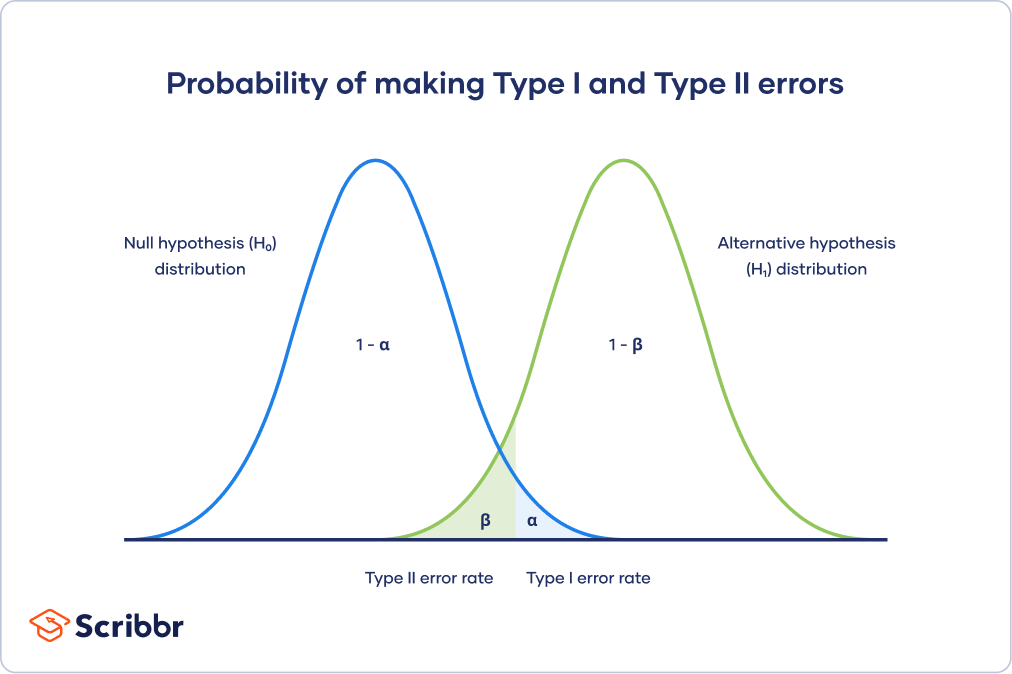
📋통계에서 검정력(=Power)이라 불리는 개념은 1에서 베타를 뺀 것이다.
즉, '검정력=Power'는 1에서 제 2종의 오류 확률을 뺀 것으로, 귀무가설이 거짓일 때 귀무가설을 기각할 확률이며, 이는 대립가설이 참일 때 대립가설을 받아들일 확률로, True Positive일 확률이다.
검정력을 간단하게 정리하면 다음과 같다.
📌 Power in statistics
= 1 - β (beta)
= 1 - type 2 error
= 1 - Pr(False Negative)
= True Positive
= probability of accepting an alternative hypothesis when the alternative hypothesis is true.
=Pr(reject H0 | H1 is true)
= Sensitivity
따라서 높은 통계적 검정력이란 의미는 제 2종의 오류의 risk가 작다는 것을 의미한다.
"High statistical power" means there is small risk of having type 2 errors(false negative).
이론적으로는 제 2종의 오류와 제 1종의 오류를 모두 줄이는 것이 좋지만 불가능하다. 알파를 작게하면 베타가 커지고, 베타를 줄이면 알파가 커진다.
예를 들어, Bonferroni correction을 하게 되면 제 1종의 오류를 줄이게 되는, 매우 보수적인 방법이다. 따라서 Bonferroni correction을 적용하면 제 2종의 오류 확률이 증가하게 된다.
반대도 마찬가지이다. 제 2종의 오류를 줄이려 한다면 귀무가설을 기각할 확률이 증가하므로 제 1종의 오류가 증가하게 된다.
아래 표를 가지고도 생각해볼 수 있다.
| Predicted | |||
|---|---|---|---|
| Positive | Negative | ||
| Actual | Positive | True Positive (TP) | False Negative (FN) = beta |
| Negative | False Positive (FP) = alpha |
True Negative (TN) | |
댓글
댓글 쓰기