통계를 살펴보면서 헷갈리는 것을 꼽으면 표준오차와 표준편차의 차이점을 들 수 있다.
표준편차와 표준오차에 대해 명확하게 나타낸 그림이 있어 가져왔다.
(출처는 그림 안에 있음)
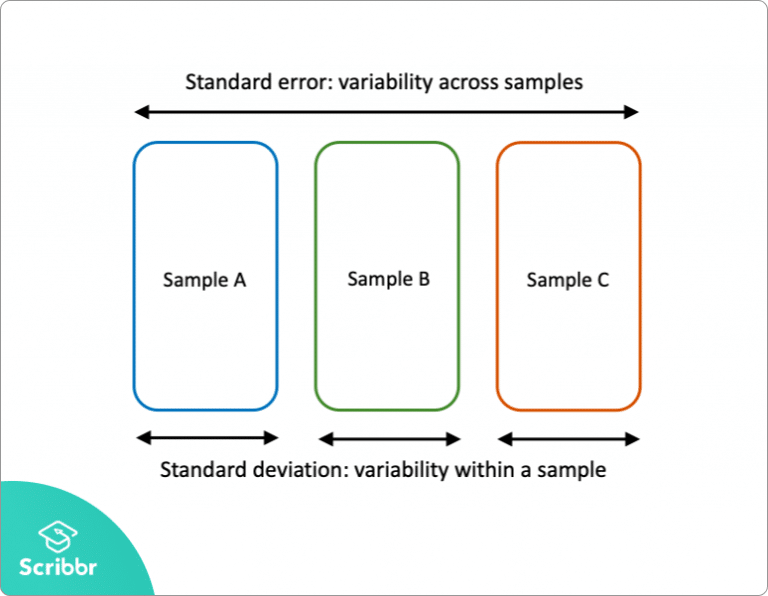
표준편차와 표준오차는 한국어로 표현했을 때, 단 한 글자의 차이밖에 없기 때문에 나만 그럴 수 있겠지만.. 더 헷갈린다.
먼저 표준편차에 대해서 살펴보자.
예를 들어, 전국의 성인 남녀의 몸무게를 조사하기 위해 1,000명을 랜덤으로 추출하고자 한다.
여기에서 모집단은 전국의 성인 남녀이고, 표본은 랜덤으로 추출된 1,000명의 성인 남녀이다.
그럼 표본의 크기가 1,000인 성인 남녀의 몸무게의 평균을 62kg, 표준편차는 4.5kg라 하자.
𝓧¡ 를 표본조사를 통해 얻은 각 관측치라고 할 때, 표준편차의 제곱을 구하는 식은 다음과 같다.
$$ S^2=\frac{\sum_{i=1}^{n}(x_i-\overline{x})^2}{n-1} $$
위 수식을 통해 표준편차란, 표본 조사로 얻은 각 관측값과 표본평균의 차이를 나타낸다고 할 수 있다.
모집단의 표준편차를 구할 때에는 분모에 n-1 대신 n으로 나누면 된다.
이번에는 표준오차를 살펴볼 차례이다.
바로 표준오차의 수식을 살펴보자.
$$ SE=s/\sqrt{n} $$
표준오차는 표준편차를 표본크기의 제곱근으로 나눈 값이다. 따라서 표본의 크기(n)가 커질수록 표준오차의 값은 작아진다.
그럼 표준오차는 무엇을 의미할까? 표준오차는 "표본평균들의 편차"를 의미한다.
원래 샘플링 오류를 줄이기 위해서 모집단에서 여러 번 표본추출을 하여 여러 표본 그룹이 있어야 하지만 현실적인 이유로 이는 불가능한 경우가 대다수다.
대부분의 경우는 모집단에서 한 번의 표본추출을 하고, 이 표본들이 모집단을 대표한다고 추정한다. 따라서 위의 예시와 같이 표본 1,000명이라는 표본의 크기 n과, 이 표본의 표준편차인 4.5kg를 이용하여 표준오차를 구하게 된다.
따라서 위 예시에서 표준오차는 4.5/√1000 ≒ 1.423이다.
표본의 수가 충분히 크면 중심극한정리에 의해 표준평균은 정규분포를 따르므로, 이를 통해 95% 신뢰구간을 구하자면, [62 ± (1.96*1.423)]가 된다.
댓글
댓글 쓰기